Category:
Data Engineering | Snowflake | Dbt
Client:
Personal Project

Following Works in progress)
Deployment in the Cloud
Credential Vaults
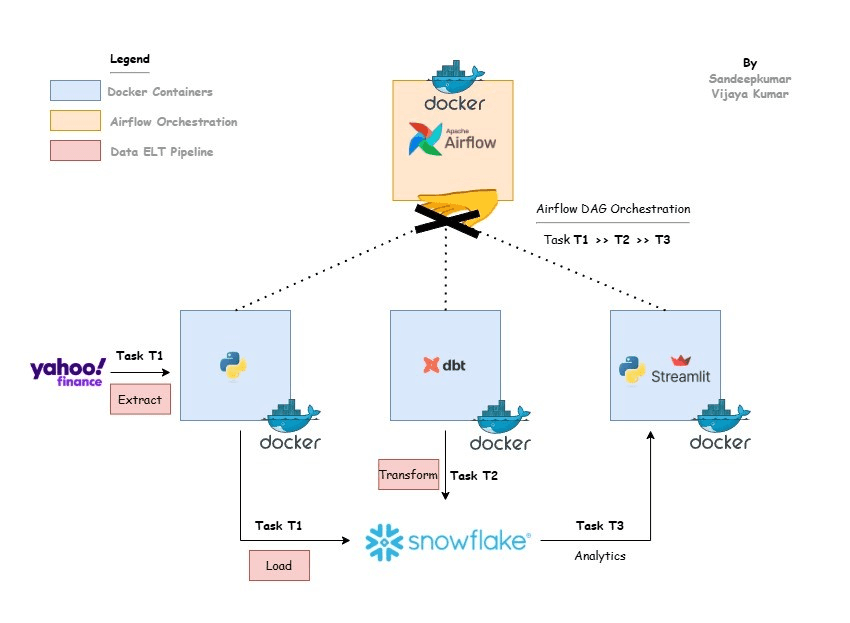
This project implements an ELT pipeline for stock portfolio analysis, leveraging Docker for containerization and Apache Airflow for workflow orchestration. The pipeline is designed to automate the data extraction, transformation, and loading (ETL) processes, followed by data analysis, all within a Dockerized environment. The system interacts with the Yahoo Finance API to fetch financial data, processes it using Snowflake and dbt, performs analysis using Python, and visualizes the results with Streamlit.
Key Problems Trying to Solve
The key problem this project addresses is automating the entire financial data pipeline, from extraction to visualization, in a highly modular and scalable environment. By containerizing each component of the pipeline (Airflow, dbt, Streamlit, ingestion, and analysis scripts), this project creates a reusable, robust system for continuous data processing, analysis, and reporting.
Demo
Coming soon...
Technical Overview
This project utilizes several modern technologies to build a scalable and efficient ELT pipeline for financial analysis:
Airflow: Orchestrates the workflow and automates the pipeline execution.
dbt (Data Build Tool): Models and transforms raw financial data stored in Snowflake.
Snowflake: A cloud data warehouse for storing and querying large datasets.
Yahoo Finance API: Source of stock market and financial data.
PySpark: Used for large-scale transformations within Snowflake.
Streamlit: Displays the analysis results in a user-friendly web app.
Docker: Each component is containerized to ensure isolation, portability, and easy scaling.
Growth & Next Steps
Expand Data Sources:
Integrate more data sources (e.g., other stock market APIs, economic indicators) to enrich the analysis.
Automated Reporting:
Implement automated reporting features in Streamlit to send daily/weekly stock insights via email or generate downloadable reports.
Scaling:
Further optimize data processing for larger datasets by integrating more advanced distributed computing techniques.
Performance Monitoring:
Integrate performance monitoring tools to track the efficiency and reliability of the pipeline.
Cloud Deployment:
Deploy the entire pipeline to a cloud platform (e.g., AWS, GCP, Azure) for better scalability and fault tolerance.

